Supply chains benchmarken met DEA
Prof. Sander de Leeuw over Data Envelopment Analysis
Jezelf met anderen vergelijken kan erg verrijkend zijn. Belangrijk daarbij is wel dat je het op de juiste manier doet. Zo zijn de traditionele methodes vaak op enquêtes gebaseerd en daardoor niet altijd even objectief. Een methode die meer betrouwbare resultaten oplevert, is Data Envelopment Analysis. Prof. dr. ir. Sander de Leeuw, chair in operations research and logistics aan de Wageningen University, legt uit hoe die methode werkt en wat de pro’s en contra’s zijn.
Wie droomt er niet van een zogenaamde ‘triple A’ supply chain, die in alle opzichten performant is? In de eerste plaats zijn bedrijven met zo’n supply chain erg wendbaar. Ze kunnen op korte termijn een antwoord bieden op veranderingen in de vraag of de bevoorrading. Verder zijn zulke supply chains vlot aanpasbaar aan structurele veranderingen en verschuivingen in de markt. Bovendien zijn die supply chains gealigneerd met het ecosysteem waarbinnen ze opereren. Daarbij wordt niet enkel rekening gehouden met de kosten en inkomsten, maar ook met sociale en ecologische randvoorwaarden. “Toegegeven, zo’n triple A supply chain is heel moeilijk te bereiken. Maar het is wel handig als je als organisatie een doel voor ogen hebt. Dat mag best ambitieus zijn. Op die manier ga je veel doelgerichter tewerk”, begint Sander de Leeuw.
Om te bepalen wat een realistische maatstaf is, is het zinvol te benchmarken met andere, soortgelijke entiteiten. Door jezelf te vergelijken met diegene die beter scoren, kun je een basis creëren om zelf te verbeteren.

Benchmarken is een kunst
Er bestaan intussen heel wat ‘supply chain performance benchmarking tools’ die individuele bedrijven helpen zichzelf met andere te meten. Enkele voorbeelden zijn: de supply chain collaboration index, de purchase managers index, de RSM US supply chain index, de global supply chain pressure index en de supply chain stability index van ASCM en KPMG.
Prof. Sander de Leeuw: “Hoewel die tools zeker hun waarde hebben, moet je altijd nagaan wat erachter steekt. Veelal werken ze met indicatoren die gebaseerd zijn op vragenlijsten. Daardoor geven ze vaak een eerder algemene indruk van de situatie. Ratiogebaseerde indicatoren kunnen ook misleidend zijn. Die methodes focussen bovendien vaak enkel op de output, veel minder op de input.”
Hanteer je liever een datagebaseerde maatstaf, dan moet je andere tools gebruiken. “Laat ons duidelijk zijn, die zijn niet makkelijk te ontwikkelen”, weet Sander de Leeuw. “Je wil immers op een zo objectief mogelijke manier entiteiten (bijvoorbeeld warehouses) met elkaar vergelijken, om vervolgens te bepalen welke entiteit het best scoort. Entiteiten zijn ook nooit precies hetzelfde en dus wil je een techniek die rekening kan houden met die diversiteit. Dat doet Data Envelopment Analysis. Bovendien wil je de mate waarin een entiteit beter is op bepaalde vlakken ook op een eenduidige manier uitdrukken. Dat kan lastig zijn.”
De meerwaarde van Data Envelopment Analysis
Data Envelopment Analysis is dus erg geschikt om supply chain entiteiten te benchmarken. DEA is een lineaire programmeringsmethode om te analyseren hoe efficiënt je bent in het converteren van input naar output. Bij input denken we bijvoorbeeld aan FTE’s, magazijnruimte, productiekosten, energie en prijzen. De output kan bestaan uit de omzet, het serviceniveau, de ecologische voetafdruk, enzovoort. Hoe minder input je gebruikt om een zekere hoeveelheid output te bereiken, hoe beter het resultaat zal zijn. En hoe meer output je genereert met dezelfde hoeveelheid input, hoe meer dat zal opleveren.
Zo’n entiteit kan eender welke duidelijk aanwijsbare eenheid zijn die beslissingen neemt. Dat kan een magazijn of een fabriek zijn, maar ook een specifieke afdeling, een winkel of zelfs een individu. De truc achter de methode is de output te schalen naar een gemeenschappelijke waarde. Zo zie je in figuur 1 met drie dimensies dat magazijn C’ dezelfde output genereert in aantal picklijnen als magazijn A met maar 72% van de input. Daaruit kunnen we afleiden dat magazijn C’ efficiënter is dan magazijn A.
Het komt erop neer dat je met DEA op een gestructureerde manier het gebied bepaalt waarbinnen je de beste oplossing tracht te zoeken. Als je DEA loslaat op de data in figuur 2, kun je op basis daarvan de grafische weergave in figuur 3 genereren. Daaruit blijkt dat magazijn A de beste score krijgt.
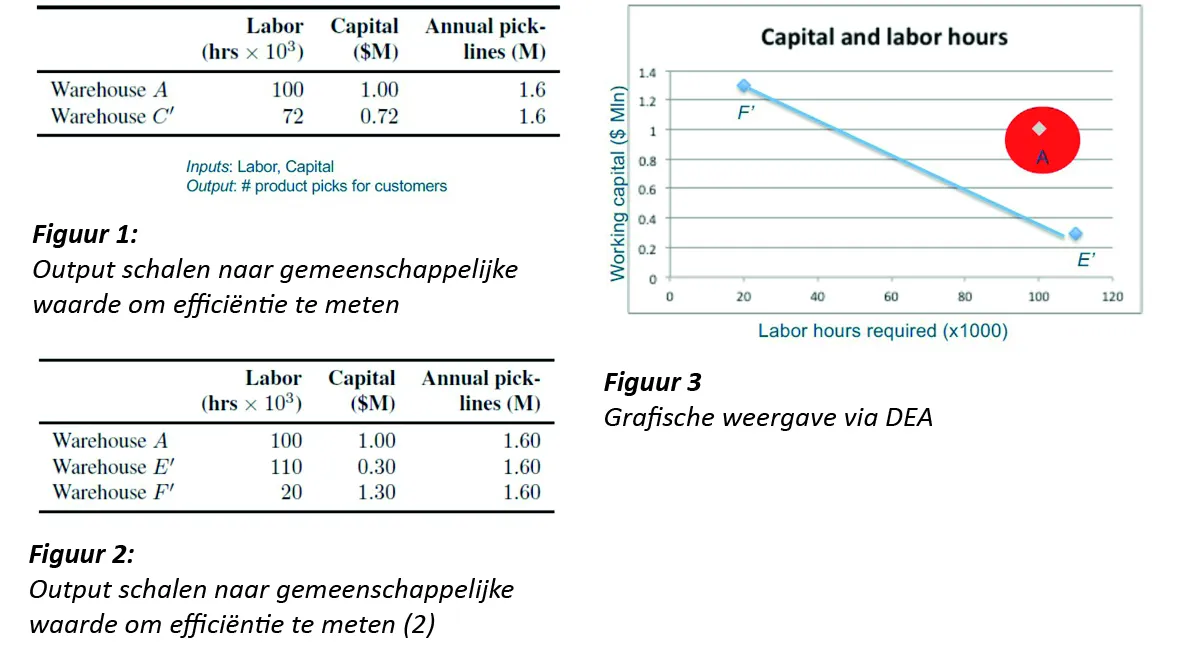
Die standaardisatietruc kun je ook voor meer dan drie dimensies toepassen, maar dan wordt de oefening uiteraard complexer. De hamvraag is wel iedere keer dezelfde: zijn er entiteiten die meer geslaagde combinaties – we noemen dit convectiecombinaties – hanteren dan wijzelf?
Klassieke DEA versus super DEA
Bij een klassieke DEA wordt de performantie van alle betrokken entiteiten gebenchmarkt. De efficiëntie van een entiteit is dan maximaal 1 (100%), waarbij je ervan uitgaat dat die entiteit dan het meest efficiënt is. Met andere woorden, dat je de output realiseert met de minste input. Technisch gezien kan de efficiëntie bij een traditionele DEA niet boven de 1 gaan.
Bij een super DEA daarentegen, neem je in de benchmarkingoefening alle betrokken entiteiten mee, behalve jezelf. Op die manier kun je nog beter zien welke mogelijke combinaties de beste uitkomst opleveren, zonder dat er een invloed van je eigen entiteit is. Pas als je die oefening hebt gemaakt, zet je de resultaten tegen je eigen entiteit. Zo’n analyse zal je nog beter helpen te bepalen welke richting je uit moet. Als je super DEA toepast, kun je voor bepaalde combinaties trouwens ook een efficiëntiegraad van meer dan honderd procent krijgen.
DEA kun je intern in de organisatie gebruiken, bijvoorbeeld om verschillende sites met elkaar te vergelijken, maar je kunt ook data van verschillende bedrijven naast elkaar leggen, als je over die gegevens beschikt. Uiteraard is het raadzaam zulke analyses niet voor elk product apart te gaan uitvoeren, maar om ze te aggregeren, bijvoorbeeld op het niveau van productfamilies.
Het is ook aan te raden bij de analyse een niet al te groot aantal ‘decision making units’ mee te nemen.
Prof. S. de Leeuw: “Met enkele tientallen entiteiten heb je al een mooie rekenproef. Ik zou zeker geen honderd entiteiten of meer meenemen. Vergelijk het met het ‘traveling salesman problem’, waar je ook een enorme rekenpuzzel krijgt als je te veel lever- en ophaalpunten incalculeert. Je doel mag ook niet het getal zijn. Het is vooral belangrijk wat daarna komt. Je moet vooral te weten komen waar je zwakke punten zitten en daar de passende acties aan koppelen. Aangezien dat een langetermijnoefening is, raad ik ook aan die analyse niet meer dan een keer per jaar te doen.”
“Gerben Scholman, student aan de Wageningen University, heeft zich voor ons over data envelopment gebogen en de analyse in Python gedaan”, gaat Sander de Leeuw verder. “Je zou dat bijvoorbeeld ook in Excel kunnen doen. Naar mijn weten zijn er niet veel bedrijven die daarvoor standaardsoftware aanbieden, maar veel optimaliseringssoftware maakt gebruik van dezelfde basisprincipes.”
Kanttekeningen bij DEA
Samengevat kunnen we stellen dat met name super DEA een interessant alternatief kan zijn voor de reguliere, indexgebaseerde benchmarkingmethodes.
Prof. S. de Leeuw: “Deze methode is immers gebaseerd op actuele bedrijfsdata. Een groot voordeel van de DEA-methode is ook dat je – doordat je altijd naar een gemeenschappelijke waarde schaalt – vrij heterogene entiteiten kunt vergelijken, of ze nu groot of klein zijn. Het is bijvoorbeeld ook mogelijk echt in de redenen voor het succes van bepaalde combinaties te duiken.”
Toch moeten we volgens Sander de Leeuw ook enkele kanttekeningen bij de methode maken. “Zo verliezen we altijd wat informatie als we gaan aggregeren”, zegt hij. “Ook worden veranderingen in de tijd met deze methode niet standaard gecapteerd. Zo kan het zijn dat een entiteit onder heel hoge druk extreem goed presteert en veel minder in andere periodes. Er bestaan weliswaar ook tijdgebaseerde methodes, maar die zijn een heel stuk ingewikkelder. Bij de DEA-methode ga je er ook uit van uit dat er een lineair verband bestaat tussen de grootte van de entiteit en de prestaties. Dat is natuurlijk niet altijd het geval. Zo zal een magazijn van 10.000 vierkante meter niet automatisch dubbel zoveel presteren als je het dubbel zo groot maakt. De overheadkosten, bijvoorbeeld, zullen niet lineair stijgen. Dat zijn wel zaken die je in het achterhoofd moet houden als je met DEA aan de slag gaat.”
Premium
Deze inhoud is enkel leesbaar voor ingelogde Value Chain abonnees.
Heeft u een abonnement op het Value Chain informatiepakket? Meldt u aan via onderstaande knop en lees het gewenste artikel of magazine online.