Big value door big data?
Prof. Jos van Hillegersberg licht waarde van big data in logistiek toe

Vandaag worden bedrijven als het ware bedolven onder data. De kunst is om er die data uit te halen die voor onze organisatie toegevoegde waarde hebben. Tijdens Supply Chain Innovations vertelde professor Jos van Hillegersberg waar binnen supply chain management de belangrijkste bronnen voor big data schuilen en hoe we er toegevoegde waarde voor onze business uit kunnen puren. Als hoogleraar aan de Universiteit Twente en voorzitter van de programmacommissie van Topsector Logistiek benadrukt hij dat big data in elk geval een opportuniteit vormt die we niet zomaar aan ons voorbij mogen laten gaan.
Dat binnen supply chain management nog eerder voorzichtig in big data wordt gegraven, ligt in elk geval niet aan de ruchtbaarheid die aan deze trend wordt gegeven. “We horen en lezen heel veel over big data. Er komen ook steeds meer leveranciers op de markt die big data-oplossingen aanbieden. Toch ervaar ik dat bedrijven vaak niet goed weten hoe ze aan zulke projecten kunnen beginnen en vooral: wat de meerwaarde voor hun organisatie kan zijn”, begint de professor.
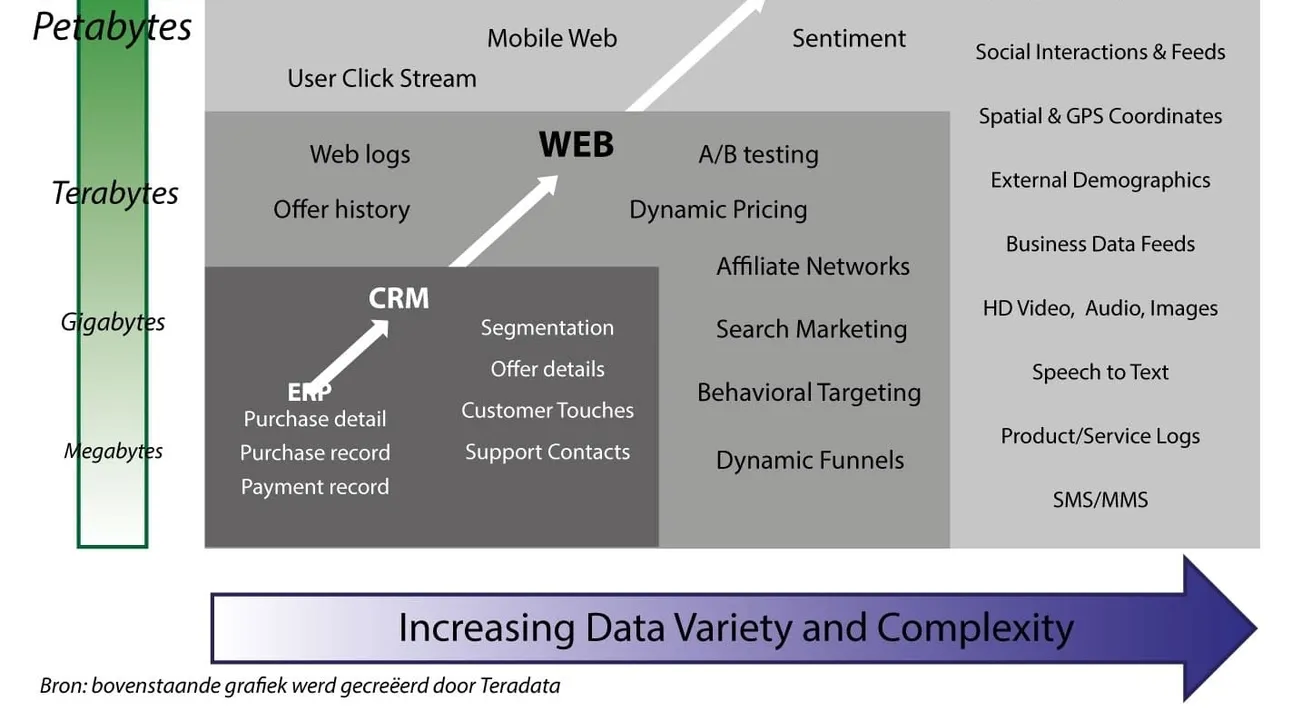
Hij benadrukt dat big data alleen maar bigger zal worden. Dat illustreert hij aan de hand van een veelzeggende figuur, die de groeiende variëteit en complexiteit van data afzet tegen de hoeveelheid informatie die op ons afkomt (zie figuur 1).
Prof. Jos van Hillegersberg maakt een onderscheid tussen diverse databronnen: “Een grote uitdaging is dat er in de loop van de jaren steeds meer bronnen bijkomen. Ruim tien jaar geleden lag de klemtoon nog op data uit de ERP-systemen, die toen volop werden geïmplementeerd. Die data zijn doorgaans vrij gestructureerd en beheersbaar. Vervolgens kwam de focus meer en meer op de klant te liggen, met tal van CRM-implementaties tot gevolg. Resultaat is dat rond je ERP nog een pak meer data komt te zitten.”
Voor een geweldige databoost heeft de opkomst van het internet gezorgd. Denken we maar aan de grote datapoel die social media vormen. “Consumenten praten over bedrijven en geven productreviews. Daar kun je als bedrijf heel waardevolle data uithalen”, klinkt het. “We merken trouwens dat steeds meer bedrijven ook hun interne communicatie over social mediakanalen gaan voeren, zoals Yammer of Slack. De data die daaruit voortvloeien, kunnen ze meenemen in hun analyses. Daarnaast laat ook het continu stijgende gebruik van mobiele apps de datastroom aanzwellen.
Daarbovenop komen de technologische mogelijkheden die Industrie 4.0 biedt, waardoor nu ook nog eens grote hoeveelheden data uit sensoren op ons afkomen. Nu al zijn er meer apparaten verbonden via het internet dan er mensen op het internet actief zijn, en dat aantal zal alleen maar vermeerderen.
“Ook tools om het gedrag van klanten en medewerkers te meten kunnen waardevolle data genereren. Hierbij denk ik bijvoorbeeld aan ‘gamification’-oplossingen, die in steeds meer omgevingen opduiken”, voegt prof. van Hillegersberg eraan toe. “Scania rust bijvoorbeeld de boordcomputer van vrachtwagenchauffeurs uit met een gameomgeving, die chauffeurs moet aanmoedigen om zuiniger te rijden. Op die manier kan de chauffeur credits verdienen, waarmee hij iets leuks kan kopen. Daarnaast kunnen productconfiguratoren – denken we maar aan consumenten die via het internet een maaltijdbox samenstellen – interessante informatie over klantenvoorkeuren opleveren.”
Last but not least wordt steeds meer open data ter beschikking gesteld. Veel overheden stimuleren die trend. Ook als bedrijf kun je overwegen om datasets open te stellen, om zo bij te dragen tot efficiëntieverbeteringen in de keten. Dankzij de intrede van open datasets kunnen we nog betere voorspellingen binnen onze supply chain maken.
Prof. Jos van Hillegersberg: “Een bijkomend gegeven is dat tegenwoordig heel wat van die data in de cloud belanden. Meegenomen is dat je data in de cloud gemakkelijker kan benaderen en openstellen voor andere partijen als je gezamenlijke analyses wil uitvoeren. Volgens een studie van AtScale onder big data professionals heeft nu al 14% al hun data in de cloud, 13% de meeste data en 26% sommige data. De verwachting is dat in de nabije toekomst 19% hun data in de cloud zal hebben, 23% de meeste data en 30% sommige data. Het aandeel data in de cloud zal dus nog sterk toenemen.”
Dat steeds meer data binnen handbereik liggen, is een goede zaak. Maar het spreekt voor zich dat het niet eenvoudig is om er de meerwaarde voor onze organisatie door te zien. “Bovendien krijg je niet alleen te maken met heel veel data, vaak zijn die ook nog eens continu in beweging. Denken we maar aan streaming data, waar een constante stroom van nieuwe gegevens wordt gegenereerd”, waarschuwt prof. Jos van Hillegersberg. “Daarnaast zijn data ook vaak erg divers van aard: gestructureerd of ongestructureerd, tekst, multimedia, gps-data, enzovoort. Verder is de kwaliteit van alle informatie die binnenstroomt niet altijd even betrouwbaar. In ERP-systemen schuilen vaak al ‘vervuilde data’. Als je met datasets van buitenaf werkt, is het risico op onbetrouwbare data nog groter.”
Extern onderzoek rond big data
De hamvraag is of het wel de moeite loont om in al die data te duiken met het oog op de creatie van meerwaarde voor ons bedrijf. “Ik ben overtuigd van wel, als we het maar op de goede manier aanpakken”, meent prof. Jos van Hillegersberg. “Als het een troost kan zijn, we zijn lang niet de eersten die de sprong wagen. Intussen zijn al veel bedrijven met big data aan de slag gegaan, weliswaar met wisselend succes. Uit die projecten kunnen we leren.”
Om een zicht te krijgen op de voorlopige ervaringen met big data, haalt Jos van Hillegersberg er het onderzoek Big Data Executive Survey 2017 bij. “In het kader van dat onderzoek hebben 50 CEO’s van Fortune 1000-bedrijven geantwoord wat zij met big data doen. Een relatief beperkt onderzoek dus, maar het geeft wel een goed idee van hoe ver grote bedrijven staan”, zegt hij.
Bijna de helft (48%) zegt in het onderzoek al meetbare resultaten met big data te hebben. Als belangrijkste struikelblok om met big data aan de slag te gaan, wordt het gebrek aan een gestructureerde organisatie aangehaald (42,6%). Ook vindt de top dat big data initiatieven worden tegengehouden, vaak door het middle management (41%). Ook technologische issues spelen vaak een belemmerende rol (27,9%). Verder worden bijvoorbeeld de afwezigheid van een coherente datastrategie (29,5%) en het gebrek aan een gedeelde visie rond big data (26,2%) als hinderpalen genoemd.
Als we inzoomen op de resultaten die met big data werden geboekt, komen vooral kostenbesparingen naar voren (49,2%). Volgens prof. van Hillegersberg kan het in die optiek interessant zijn om datasets te vergaren, daarbinnen inefficiënties te detecteren en die vervolgens aan te pakken. Ook biedt big data vaak toegang tot innovatieve oplossingen (44,31%) of geeft het de impuls om nieuwe oplossingen of services (36,1%) te ontwikkelen. Waar bedrijven veel minder vaak in slagen is om via big data de business op de toekomst af te stemmen, nieuwe vaardigheden binnen de organisatie te ontwikkelen en een datagedreven cultuur te realiseren. Daaruit kunnen we afleiden dat vooral de cultuurverandering als voedingsbodem voor big dataprojecten een uitdaging vormt.
“Uit onderzoek van de Nederlandse Kamer van Koophandel bij 4.100 kmo’s blijkt dat kleinere bedrijven toch wel wat schrik hebben voor al die data. Maar liefst 49% ziet er totaal geen waarde in voor hun bedrijf. Ze vinden ook heel vaak dat ze gewoonweg te weinig vaardigheden hebben om met big data aan de slag te gaan. Tot nader order lijken het dus toch vooral de grotere bedrijven te zullen zijn die het voortouw nemen. Maar dat ook de kleinere zullen volgen, daar ben ik wel zeker van”, voegt prof. van Hillegersberg eraan toe.

Resultaten uit eigen onderzoek
Om bedrijven van eigen bodem beter vertrouwd te maken met big data en zo de toepassingen aan te zwengelen, doet de Universiteit van Twente samen met Dinalog (Dutch Institute forAdvanced Logistics) intensief onderzoek naar het potentieel. In het kader hiervan licht prof. Jos van Hillegersberg drie projecten toe die zijn vakgroep aan de Universiteit Twente samen met enkele bedrijven en overheidsorganen heeft uitgevoerd.
Binnen het eerste onderzoek werd geprobeerd via datamining van AIS-data de aankomsttijden van zeeschepen adequaat te voorspellen. AIS is een navigatiesysteem dat helpt om schepen snel te lokaliseren en te identificeren. Zo zendt de AIS-zender op een schip periodiek statische informatie (o.a. naam, afmetingen en type schip), dynamische informatie (o.a. positie, koers, snelheid) en reisgebonden gegevens (o.a. de bestemming) uit naar andere schepen. “Tijdens dat project is gebleken dat de sensoren op die trajecten heel veel verkeerde en gebrekkige data uitsturen. Met behulp van lerende algoritmes hebben we die missende data trachten in te vullen, zodat we tot betrouwbare routepatronen en dito voorspellingen kwamen. Dat was een zeer belangrijk aandachtspunt ”, legt prof. van Hillegersberg uit. “Er bestaat veel regelgeving over de mate waarin je AIS-data al dan niet kan minen. Omdat je met dat soort toepassingen de privacy rond schepen niet schendt, kan dit wel. Maar de regelgeving rond privacy is dus wel iets waar je als big data-gebruiker rekening mee moet houden als je de grenzen van je eigen organisatie overschrijdt.”
Een tweede onderzoek focuste zich op de farmaceutische industrie. “Wereldwijd wordt heel wat – vaak dure – medicatie verscheept. Vaak is het belangrijk dat bepaalde temperaturen niet worden overschreden. Ook zijn zulke ladingen behoorlijk diefstalgevoelig. Binnen het kader van dit onderzoek hebben we bekeken welke waardevolle informatie we uit sensoren kunnen halen om zulke ketens te verstevigen. Zoals waar een bepaalde pallet staat, of de temperatuur binnen de toegelaten marge zit en of die nog wel de geplande route volgt. Een van onze partners in dit project was Panalpina, die voor het project zijn warehouses met de nodige antenne-infrastructuur heeft uitgerust”, licht prof. Jos van Hillegersberg toe. “Toen we dit project startten, hebben we ons gefocust op de monitoring. Zo kon bijvoorbeeld worden beslist een transport niet verder te laten gaan als bepaalde temperaturen werden overschreden. In een later stadium hebben we gemerkt dat het ook heel interessant was om achteraf analyses te maken op basis van datasets. Zo werd bijvoorbeeld duidelijk welke partijen de grootste frustratie in de keten veroorzaken.”
Het meest recente onderzoek betreft een Nederlands koel- en diepvriesmagazijn, waar heel veel internationale transporten aankomen. “Een groot pijnpunt hier was dat de vrachtwagens niet altijd op de afgesproken tijdstippen aankwamen, wat de operaties binnen het magazijn verstoorde. Op basis van big data hebben we voor dat bedrijf trachten te voorspellen welke vrachtwagens te laat of te vroeg zouden komen”, aldus de professor. “In dit geval konden we gebruikmaken van de open data, waaronder alle file-informatie die Rijkswaterstaat ter beschikking stelt. Die data hebben we gekoppeld aan bijvoorbeeld data over het weer, wat opnieuw open data is. Die gegevens zijn we vervolgens gaan combineren met de bewegingsdata van de vrachtwagens. Maar in tegenstelling tot wat het bedrijf dacht, vormden het weer en de files slechts een klein gedeelte van de variatie. Een veel grotere impact hadden aspecten als rij- en rusttijden, contractafspraken en zelfs het niveau van de vrachtwagenchauffeur. Met andere woorden, big data is interessant, maar je mag de rol van contractuele afspraken en de mensen die achter de activiteiten zitten niet zomaar uitvlakken.”
Eerst denken, dan IT
Een grote valkuil bij big data-implementaties is dat je je al te snel laat verleiden door gesofisticeerde software en sensoren. Prof. van Hillegersberg adviseert dan ook om niet meteen bij de technologie te starten. Inzicht krijgen in je data, vervolgens een goed werkend model uittekenen en pas daarna een passende software zoeken, is de boodschap. In de eerste plaats moet je dus goed weten wat je precies met big data wil doen.
Prof. Jos van Hillegersberg: “In wezen kun je drie doelen onderscheiden. Zoals ook het onderzoek onder de Fortune 1000-bedrijven uitwees, kun je in de eerste plaats data verzamelen om inefficiënties te detecteren en aan te pakken. Hier ligt de focus dus op ‘operational excellence’. Daarnaast kan de focus liggen op optimalisering, bijvoorbeeld van je logistieke netwerk. Dan krijgt big data een meer strategische rol. Een derde doel dat big data kan hebben, is het beter begrijpen van je klanten om vervolgens beter op hun wensen in te kunnen spelen.”
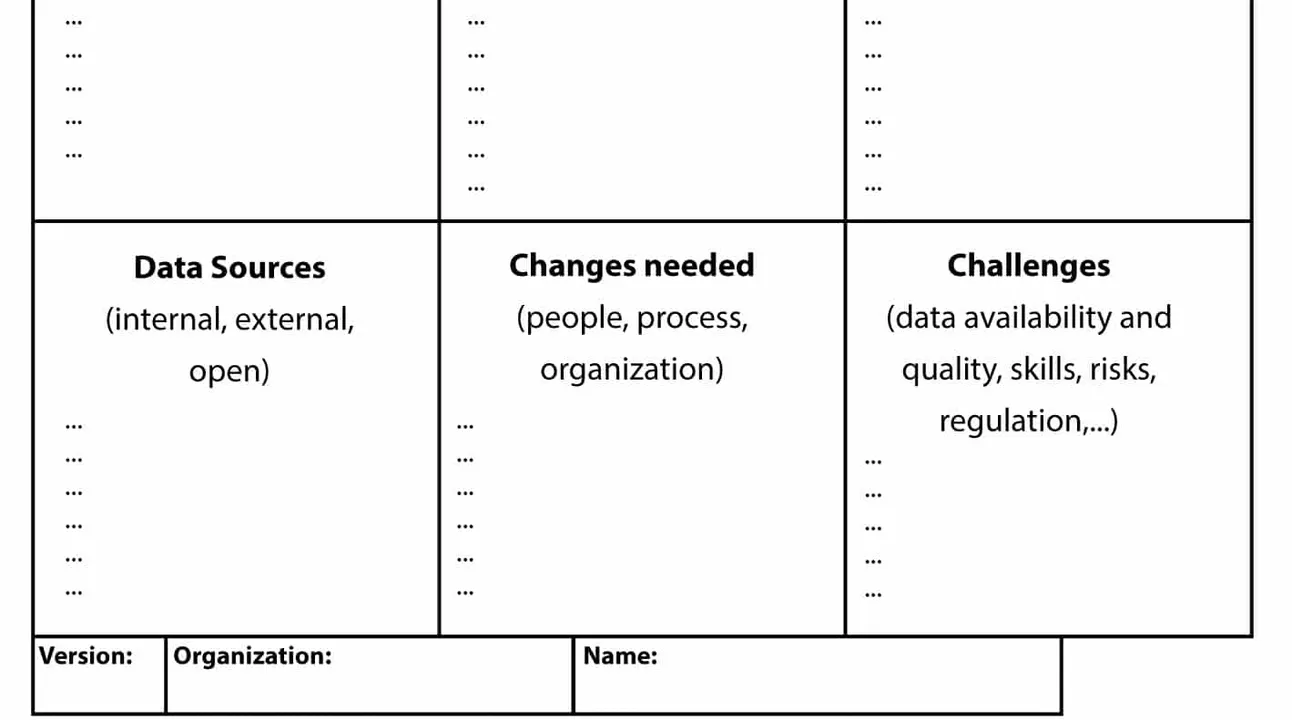
Om voor een betere start met big data te zorgen, heeft prof. van Hillegersberg een canvas uitgewerkt. Die kunnen bedrijven gebruiken als ze brainstormen over de waarde van big data voor de organisatie (zie figuur 2). “Zo moet je jezelf steeds de vraag stellen welke problemen je precies hebt en hoe je die met big data zou kunnen oplossen. Zeker als je groots denkt, zal een business case de nodige investeringen moeten kunnen verantwoorden. De canvas doet je ook nadenken over de uitdagingen, de databronnen die je wil gebruiken en – niet onbelangrijk – de veranderingen die dat alles van je organisatie zal vergen.”
Waaier aan software
Een vraag die prof. van Hillegersberg heel vaak krijgt, is wat nu de beste software is om big data onder handen te nemen. “Een heel lastige vraag. Het is ook onmogelijk om er slechts enkele naar voren te schuiven. Er bestaan heel veel tools om big data te analyseren en er komen er constant bij. We hebben er recent meer dan tachtig onder de loep genomen en toen we klaar waren, zagen we alweer nieuwe tools opduiken. Bovendien zal de beste keuze afhangen van je type data, je organisatie, de mensen die ermee moeten werken, enzovoort”, legt hij uit.
Daarnaast moet je je realiseren dat big data verwerken tot een hapklare brok meerdere stappen behelst. “In een eerste stap moet je de data ‘schoonmaken’ en voorbereiden voor verder gebruik. Pas dan zijn ze klaar voor verdere analyse. Die stap wordt heel vaak vergeten, terwijl het wel het grootste deel van het werk is. Dat geldt zeker als je te kampen hebt met overvloedige data, uit sensoren bijvoorbeeld. Je ziet dat dergelijke tools steeds meer kunstmatige intelligentie bevatten, zodat rariteiten in je data vlugger gedetecteerd worden. Tools binnen dit domein zijn bijvoorbeeld Alteryx, Trifacta en Paxata. Een aardige open sourcetool is verder openrefine.org”, aldus prof. van Hillegersberg.
In een volgende fase kun je de beschikbare data analyseren en visualiseren. “Om dat te doen bestaan er enorm veel tools, van gratis tot peperduur. Bekende spelers op dit terrein zijn SAS, Qlik, R, SPSS, Tableau, Statistica, Knowledge Studio en Google FusionTables. Een bekende open sourceoplossing die hier kan helpen is knime.org.”
Tot slot kunnen we op onze data kunstmatige intelligentie en datamining toepassen. “Aan de ene kant biedt dat het voordeel dat je hiervoor minder statistische kennis nodig hebt, aan de andere kant bestaat het risico dat je zo de waarde van je analyses minder goed kunt inschatten. Met oplossingen zoals IBM Watson analytics en Wolfram Alpha kun je heel veel, maar je krijgt wel te kampen met een blackbox”, waarschuwt prof. van Hillegersberg. “In dit domein vind je eveneens een aantal opensource tools als rapidminer.com, waarmee je bijvoorbeeld op basis van historische data voorspellingen kunt maken.”
Binnen al die segmenten groeit het aanbod oplossingen zeer snel. Bovendien worden de tools steeds goedkoper, sneller en krachtiger. “Terwijl tien jaar geleden enkel grote bedrijven zich degelijke big data tools konden veroorloven, zijn die nu ook voor kmo’s heel toegankelijk”, weet prof. van Hillegersberg. “Social media mining, bijvoorbeeld, was vroeger heel lastig. Nu bestaan er meerdere tools waarbij je simpelweg via sleutelwoorden kunt gaan kijken wat er op social media over jouw organisatie wordt gezegd. Met de tool van het Nederlandse bedrijf open.coosto.com kun je ook gemakkelijk aan sentiment mining gaan doen, waarbij je kunt inzoomen op negatief of positief nieuws. In feite kun je daar gratis mee experimenteren. Pas als je dieper wil graven, moet je betalen.”
Maar hoe sterk je ook van wal steekt, prof. van Hillegersberg waarschuwt dat een datagedreven organisatie niet van de ene dag op de andere dag ontstaat. “Hiervoor moet je verschillende stappen doorlopen, gaande van eerste opportunistische stappen naar een organisatie waar medewerkers systematisch processen gaan bestuderen aan de hand van data-analyses. Dat betekent uiteraard dat je intern heel veel kennis zult moeten opbouwen. Dat kun je op verschillende manieren doen. Zo bestaan er allerlei communities of je kunt intekenen op online cursussen. Uiteraard word je niet zomaar een echte data scientist voor wie big data geen geheimen heeft. Toch ben ik ervan overtuigd dat heel wat professionals binnen de organisatie er baat bij hebben om zich een deel van die vaardigheden eigen te maken. Verder kun je ook teams van studenten op je data loslaten tijdens bijvoorbeeld een hackaton. Zulke initiatieven vinden steeds vaker plaats. Daarnaast bestaan er ook platformen zoals Kaggle – ondersteund door mensen die van data science smullen – die voor jou analyses maken. Er zijn dus tal van manieren om met big data te experimenteren.”
“Ik ben ervan overtuigd dat we binnen supply chain management nog maar aan het begin van big data staat”, besluit prof. Jos van Hillegersberg. “Zeker als meerdere partijen bereid zijn hun data samen te leggen, kan dat zeer interessante perspectieven openen. Binnen de Universiteit Twente beschouwen we het als onze taak mee te werken aan nieuwe modellen die zulke initiatieven ondersteunen én in de rand daarvan alle uitdagingen bij big data-implementaties in kaart te brengen.”
Inloggen/registreren
Om deze content te lezen, moet u zich inloggen.
Log in of registeer nu via onderstaande knop en krijg toegang tot deze inhoud.


