AI4CAST: intelligent voorspellen en plannen met AI
VIL onderzoekt toepassing van artificiële intelligentie in de supply chain

Een goede planning is niet alleen het halve werk, in de wereld van de logistiek maakt de kwaliteit van de planning steeds vaker ook echt het verschil. VIL, het innovatieplatform voor de logistieke sector in Vlaanderen, onderzocht of, hoe en in welke mate artificiële intelligentie (AI) kan bijdragen tot het verbeteren van de planning van de supply chain. “De tijd dat een rekenblad in Excel volstond om te plannen, ligt lang achter ons”, stelt Dirk Jocquet, projectleider bij VIL.

Een hogere nauwkeurigheid, een aanzienlijke tijdwinst, een effectieve kostenbesparing en een optimale (interne) klanttevredenheid: dat zijn de belangrijkste voordelen die het gebruik van AI-technieken bij het voorspellen en plannen van de supply chain kan opleveren. Zo blijkt althans uit een studie die VIL sinds april 2020 uitvoerde onder de noemer AI4CAST. Daarvoor bundelde VIL de krachten in een consortium met de West-Vlaamse hogeschool Howest en de technologie-experts van Sirris, het collectief centrum van en voor de technologische industrie. De resultaten van dat logistieke onderzoeksproject publiceerde VIL eerder dit jaar in een officieel verslag, dat leden van VIL gratis en niet-leden tegen betaling, op de website van VIL kunnen downloaden.
Meer complex, minder voorspelbaar
Om de aangehaalde voordelen bij het gebruik van AI in de supply chain te kunnen realiseren, moet er wel eerst aan een aantal basisvoorwaarden zijn voldaan. “Om te beginnen moet er bij alle betrokken partijen in de supply chain een minimumniveau van datamaturiteit en data governance aanwezig zijn”, vertelt Dirk Jocquet. “Verder moet er tussen al die partijen een wederzijds vertrouwen bestaan. Een geschikt dataplatform kan dat vertrouwen technisch ondersteunen en stimuleren.”
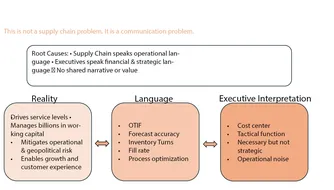
Maar laat ons niet op de mogelijke oplossingen vooruitlopen en eerst kort even stilstaan bij de belangrijkste problemen en uitdagingen waar supply chain managers vandaag mee worstelen. Helemaal bovenaan de lijst prijken de groeiende complexiteit en toenemende onvoorspelbaarheid van de hedendaagse supply chains. “Voorraden zijn beperkt en ‘just in time’ blijkt steeds vaker de norm”, vat Dirk Jocquet samen. “Het gevolg is dat onverwachte gebeurtenissen zeer snel grote logistieke problemen kunnen veroorzaken, zoals acute en in het geval van de coronapandemie zelfs chronische leververtragingen. Die treffen alle partijen in de keten, met inbegrip van de eindklanten – externe, maar ook interne. Dat kan uiteindelijk leiden tot een lagere klantentevredenheid. Daarbij kunnen de oplossingen voor die logistieke problemen op hun beurt ook weer bijkomende kosten met zich meebrengen.”
Zweepslageffect
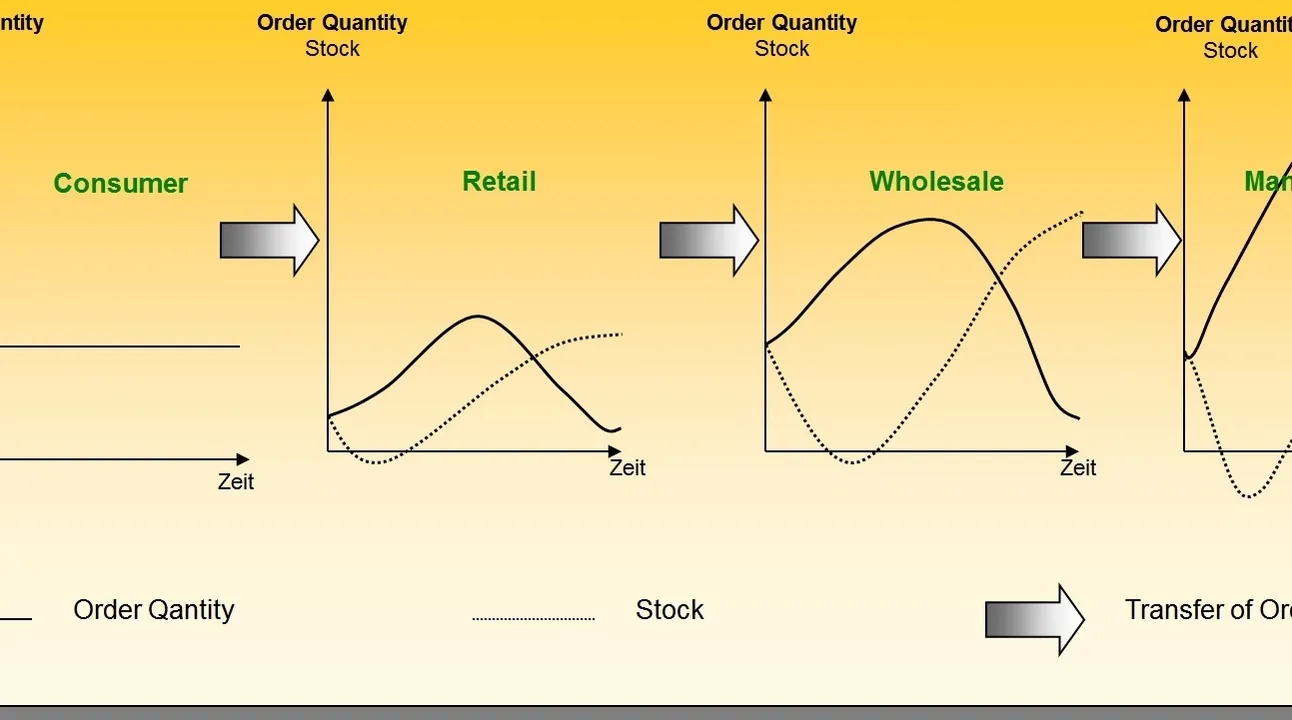
In dat verband haalt Dirk Jocquet ook het zogenoemde zweepslageffect (ook wel opslingereffect of bullwhip effect) aan: het probleem dat kan ontstaan door de fluctuerende vraag van orders binnen een supply chain. Die fluctuerende vraag bemoeilijkt het voorspellen van het aantal te produceren producten. Daardoor kan een voorraadtekort binnen de kortste keren omslaan in een voorraadoverschot, met als gevolg dat de volledige keten, van de eerste tot de laatste schakel, aan efficiëntie verliest.
Bij wijze van voorbeeld verwijst de projectleider naar het relatief nieuwe fenomeen van de influencers op sociale media. “Als zo’n Instagram-influencer een bepaald product promoot, kan het gebeuren dat zijn of haar volgers plots massaal aan het bestellen slaan. Maar retailers, producenten en leveranciers zijn niet altijd klaar om aan die onverwacht sterke vraag te voldoen. Het gevolg is dat zij, vrij impulsief vaak, hun voorraden zo snel mogelijk beginnen aan te vullen. En hoe verder je dan in de keten opschuift – hoe verder weg van de klant, met andere woorden – hoe groter die voorraden doorgaans worden. Dat is het typische zweepslageffect, dat de inefficiëntie in de keten vergroot en daarmee ook de kosten voor de verschillende schakels in die keten doet stijgen en hun winst doet afnemen.”
Ketenbrede samenwerking
“Dat zweepslageffect is vooral te wijten aan het gebrek aan samenwerking in de supply chain”, meent Dirk Jocquet. Zo delen de verschillende schakels in die keten niet altijd de nodige informatie. In alle schakels afzonderlijk worden ook telkens aparte vraagprognoses opgesteld, zonder onderling af te stemmen. Op die manier stapelen de onzekerheden en discrepanties zich doorheen de supply chain op.
De oplossing ligt voor de hand: een ketenbrede samenwerking is een essentiële voorwaarde om de logistieke forecasting en planning te optimaliseren. Om zo’n samenwerking met succes te realiseren, zijn volgens VIL drie basiselementen vereist: data governance, vertrouwen en (meer)waardecreatie.
Hiërarchie van databehoeften
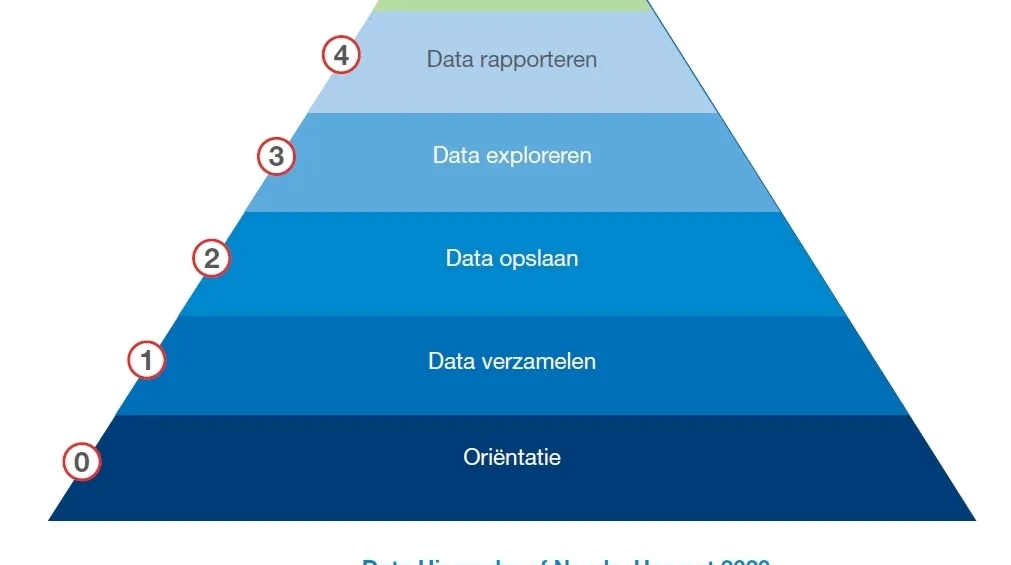
“Aan data is er geen gebrek”, aldus Dirk Jocquet. “Misschien zijn er vandaag zelfs te veel data beschikbaar. We slagen er bovendien steeds beter in om die overvloed aan data te capteren, bijvoorbeeld via sensoren. Maar met het verzamelen en opslaan van data begint het proces van dataverwerking pas. Daarna moet je die data ook nog eens gaan exploreren en met behulp van BI analyseren of rapporteren, voor je ze effectief kunt inzetten en ten slotte AI-technieken erop loslaten.”
In dat verband wijst VIL op de ‘Data Hierarchy of Needs’, een framework dat Howest als academische projectpartner ontwikkelde naar analogie met de menselijke behoeftepiramide van Maslow. De datapiramide van Howest telt zes niveaus, van datacollectie tot AI. Ze laat toe de datamaturiteit van een organisatie met een hoge mate van objectiviteit in kaart te brengen. Hoe ervaren een organisatie met data omgaat, bepaalt immers mee de slaagkansen voor het gebruik van een geavanceerde technologie als AI. Concreet helpt het framework organisaties door hen een overzicht te bieden van de stappen die ze nog moeten ondernemen op basis van hun positie in de piramide.
Data governance
Het is van het grootste belang dat een organisatie eerst de onderste drie niveaus of lagen van de datapiramide met succes heeft doorlopen. Dan pas kan ze het erop wagen de stap naar de bovenste drie lagen te zetten. Vooral de derde laag verdient daarbij de volle aandacht. “Daarin verken je de data en spoor je eventuele fouten op. Zo kun je de datasets ook opschonen en transformeren voor gebruik”, legt Dirk Jocquet uit.
Op dat derde niveau voeren organisaties ook vaak een databeleid in, om te bepalen aan welke kwaliteitsparameters hun data moeten voldoen. Die kwaliteitsbewaking behoort tot het domein van de data governance. “Maar zo’n databeleid alleen volstaat niet”, klinkt het nadrukkelijk. “Je mag nog de allerbeste data governance van de hele wereld hebben, uiteindelijk heb je toch de data nodig die het meest afgestemd zijn op jouw eigen unieke noden en wensen. Dat betekent heel concreet dat je jouw data zal moeten aanpassen aan de vereisten van de logistieke forecasting en planning die jij nastreeft. Het betekent ook dat je je data zal moeten corrigeren en verrijken met andere data. Zijn je data niet correct, dan zullen klanten bij het online bestellen bijvoorbeeld gefrustreerd moeten vaststellen dat een artikel dat volgens jouw website op voorraad was, plots toch niet voorradig is. Verrijk je je data niet met data van andere spelers in jouw logistieke keten, dan zal je met blinde vlekken blijven kampen. En de typische reactie op een blinde vlek is, zoals het zweepslageffect duidelijk aantoont, een overreactie: je gaat voorraden over- of onderschatten.”
Draaiboek voor intelligente forecasting
Om de datamaturiteit van een organisatie nog beter te kunnen inschatten, specifiek met het oog op het gebruik van artificiële intelligentie, ontwikkelde Howest ook een ‘AI Capability Assessment’ voor data. Net als de ‘Data Hierarchy of Needs’ telt ook die AI-capaciteitsbeoordeling vijf niveaus van datamaturiteit, waarbij enkel organisaties die niveau vier of vijf al bereikt hebben effectief klaar zijn om AI-technieken in te zetten voor de forecasting en planning van hun supply chain. Het verschil met die ‘Data Hierarchy of Needs’ is dat de AI-capaciteitsbeoordeling niet enkel de data governance in rekening brengt, maar ook de datakwaliteit en de toegang tot de data.
Om organisaties te helpen naar maturiteitsniveau vier en vijf op te klimmen, maakte VIL ook werk van een overkoepelend algemeen draaiboek voor intelligente forecasting. “In de loop van het project zagen we veel bedrijven worstelen met hun beschikbare datasets”, herinnert Dirk Jocquet zich. “Want het is niet omdat je over data beschikt, dat die data ook waardevol zijn om in je supply chain te verwerken. Vandaar ons idee om een draaiboek te voorzien met concrete stappen en best practices om de datamaturiteit op te krikken.” Het draaiboek is vooral bedoeld voor bedrijven met weinig of geen ervaring in het gebruik van data om de eigen bedrijfsprocessen te verbeteren, laat staan dat ze die data kunnen of willen delen met andere bedrijven binnen een samenwerkingsketen.
Wederzijds vertrouwen
Een minimumniveau van datamaturiteit en data governance is het eerste basiselement dat nodig is om een succesvolle samenwerking uit te bouwen doorheen de supply chain. Voldoende wederzijds vertrouwen tussen de betrokken partijen vormt het tweede basiselement. “Als je binnen een supply chain data deelt, moet je erop kunnen vertrouwen dat die data alleen voor het beoogde doel worden gebruikt en buitenstaanders geen toegang ertoe hebben. Je wilt immers niet dat jouw data op straat voor iedereen en dus ook voor je concurrenten te grabbel liggen.”
Een correct opgezet datadelingsplatform kan dat onderlinge vertrouwen technisch ondersteunen en faciliteren. “Voor ons onderzoeksproject hebben we gekozen voor Nextcloud, omdat het een honderd procent open-source, zelf-gehost en GDPR-compliant platform is. Dat is bij uitstek geschikt voor het uitwisselen van betrouwbare gedeelde data”, verduidelijkt Dirk Jocquet.
(Meer)waarde creëren
Als die eerste twee basiselementen voorhanden zijn, is het nog zaak om (meer)waarde te creëren voor alle partijen in de supply chain: het derde basiselement. Dat doe je door de juiste AI-technieken en -modellen voor forecasting en planning toe te passen (zie kader). Als alles goed gaat, zorgen zij voor meer nauwkeurige plannen en prognoses. Doordat dat het zweepslageffect tegengaat, kun je ook voorraadtekorten en -overschotten vermijden en effectief kosten besparen. “De combinatie van de drie basiselementen kan tot een kwart – en zelfs meer – aan kostenbesparingen opleveren”, rekende Dirk Jocquet uit. Wijzigingen aan de data worden nu bovendien in real time verwerkt, wat ook een aanzienlijke tijdswinst kan opleveren. “De data van gisteren zijn meer dan ooit oude data”, beseft de projectleider. ‘Last’ maar zeker niet ‘least’ zien alle partijen in de samenwerkingsketen ook de (interne) klanttevredenheid verbeteren.
AI Starter Kits
Grote bedrijven kunnen eigen, toegewijde teams van datawetenschappers inzetten om AI-technieken te ontwikkelen en toe te passen. Kleinere bedrijven hebben extra steun nodig om de vereiste AI-competenties in huis te halen. Daarom ontwikkelde Sirris, het collectief centrum van en voor de technologische industrie, een handige AI Starter Kit set. Die bevat een verzameling autodidactisch materiaal met AI-oplossingen voor specifieke industriële problemen.
Zes van die AI-oplossingen of Starter Kits werden relevant geacht in het kader van het AI4CAST-project, waarbij ook Sirris als technologiepartner van VIL nauw betrokken was. Zo konden de deelnemers aan het project onder meer gebruikmaken van de AI Starter Kit voor het voorspellen van de vraag (‘Resource demand forecasting’), maar ook van de Starter Kits voor geavanceerde visualisatie (‘Advanced visualization’) en dataverkenning (‘Data exploration’).
Proofs of Concept
Verschillende van die AI-technieken zijn ook aan bod gekomen in de drie PoC’s (Proofs of Concept) die werden uitgevoerd in het kader van het AI4CAST-project. Het doel van de eerste PoC was de vraag van een retailer (Colruyt) aan een producent (Procter & Gamble) zo goed mogelijk te voorspellen (‘demand forecasting’), evenals de verkoop van een specifiek aantal productcategorieën van P&G door diezelfde retailer. Op die manier wou P&G voorraadtekorten en -overschotten tegengaan.
Deze PoC bracht een aantal typische dataproblemen aan het licht waar de gehele logistieke sector mee worstelt en die eigen zijn aan het samenbrengen van datasets uit verschillende bronnen. Zo is met name standaardisatie van de data, bijvoorbeeld door een veralgemeend gebruik van de EAN-code, van groot belang. “Zo vermijd je dat elk bedrijf en zelfs elke afdeling een andere taal hanteert voor hetzelfde product”, aldus Dirk Jocquet.
“Om klaar te zijn voor de toekomst, moeten we blijven werken aan het verbeteren van de kwaliteit van onze supply chain en productdata”, getuigt Lieven Deketele, technical director Supply Innovation bij P&G. “Met AI4CAST konden we al eens vooruitblikken hoe artificiële intelligentie belangrijk kan worden voor een betere supply chain planning.”
De tweede PoC richtte zich op het efficiënter inzetten van het logistiek personeel en de opslag van de vooral gepalletiseerde bewegingen bij transportbedrijf ECS. Ook hier bleek dataconsolidatie uit verschillende interne bronnen geen evidentie om tot een volledige dataset te komen. Maar een goede data governance, aangevuld met het isoleren van pieken en onregelmatigheden die niet tot het normale businesspatroon behoren, dient zeker als basis om een goede voorspelling te kunnen doen.
De derde PoC, ten slotte, focuste op het verbeteren van de operationele werking bij ICO (International Car Operators), specialist in de behandeling en opslag van roll-on-roll-off-cargo. Daarbij gaat het concreet om het laden en lossen van voertuigen op RORO-schepen, gemeerd aan verschillende kades. Afwijkingen op de ‘lead times’ van de voertuigen en wijzigingen in de volgorde van laden of lossen van de schepen zorgen voor onvoorspelbaarheid. Door bestaande data aan te vullen met realtime-informatie kan ICO die lead times beter voorspellen.
Premium
Deze inhoud is enkel leesbaar voor ingelogde Value Chain abonnees.
Heeft u een abonnement op het Value Chain informatiepakket? Meldt u aan via onderstaande knop en lees het gewenste artikel of magazine online.